

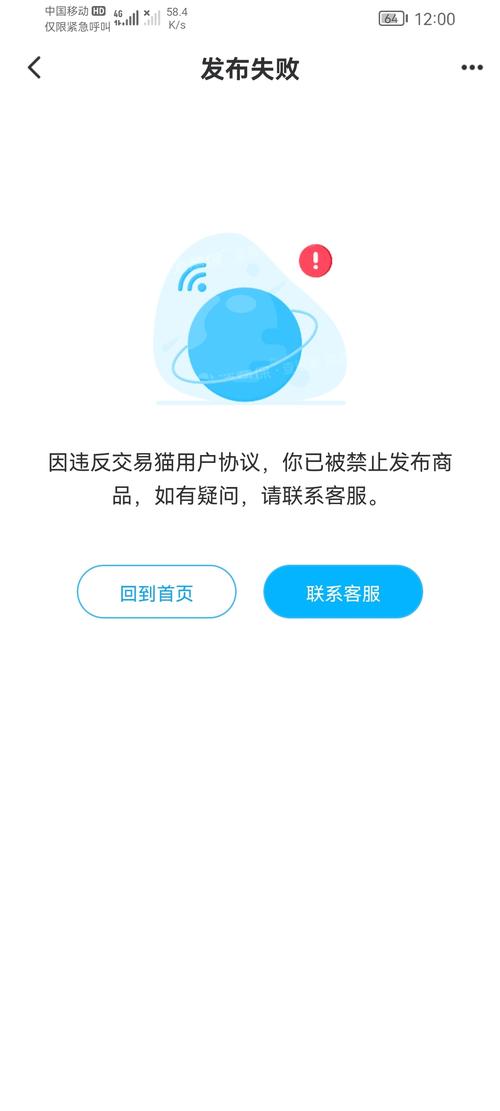
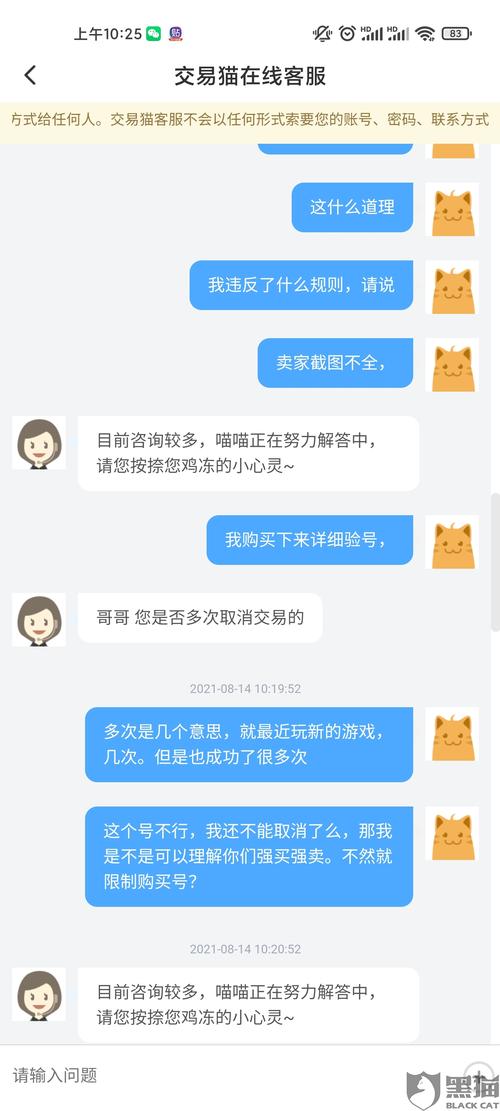
交易猫ip地址封了怎么办?(爬虫服务器被屏蔽,不要慌,咱们换一台香港站群服务器)
交易猫ip地址封了怎么办?
1、技术处理:使用高级爬虫爬取数据信息,能够更好的能够保护本机的信息,就算IP被封禁了,也只是代理IP并不影响自己的真实IP。
 (图片来源网络,侵删)
(图片来源网络,侵删)2
/3
2、网络处理;IP被封停后,本地IP将不能再访问目标网站。但是设置了代理服务器的话,浏览器可以访问该网站,可以在命令行加路由。
 (图片来源网络,侵删)
(图片来源网络,侵删)3
/3
这个路由重新开机就没有了。IP地址mask子网掩码默认网关。即便不小心重启,该网关还是在的。
 (图片来源网络,侵删)
(图片来源网络,侵删)网站总出503错误怎么解决?
503表示服务器暂时无法处理某一请求。这既有可能是服务器过载导致的,也有可能是服务器屏蔽了你的请求。第一一点,你需要确认目标网站有没有禁止爬虫访问(最简单的方法是查询robots.txt)。一般建议尊重网站的设置。
Be polite.第二,如果是因为服务器过载导致503,请降低爬虫的并发访问数量,并且延长各个请求之间的间隔时间(比如设置为10-20分钟)。
最复杂的情况是,网站设置了爬虫陷阱。取决于具体设置,这里面的情况千差万别——通常可以采取的应对措施包括降低并发数量(别表现的那么像机器)、更换user-agent设置、更换访问IP等。
这种情况本质上需要个例分析,另外,题主是自己写的爬虫还是应用的第三方库?对于“程序不跑也不结束”这个情况,如果是后者,建议调阅log(有的库可能需要调用python的标准logging库)然后查询库文档。
如果是前者,可以考虑加入更为细致的状态查询记录功能并相应调试(比如,是不是卡在某个人机验证页面上了?)
可能是手机系统出现问题,如果系统版本比较低或者是手机系统存在某些漏洞未修复或业务功能未优化,就会使手机在使用APP等应用过程中出现503错误的情况,建议更新到最新的系统使用
为什么爬虫需要代理ip?
因为有反爬虫机制,只能换IP,可以选择芝麻HTTP代理
爬虫选择IP代理不能盲目选择,这关系到我们采集效率的高低,主要需要满足以下几点:
1、IP池要大,众所周知,爬虫采集需要大量的IP,有的时候会每天需要几百万上千万的调用,如果IP数量不够,那爬虫的工作也无法进行下去。所以企业爬虫一般要找实测至少百万以上的IP,才能确保业务不受影响。
2、并发要高:爬虫采集一般都是多线程进行的,需要短期内内获取海量的IP,如果并发不够,会大大降低爬虫采集的数据。一般需要单次调用200,间隔一秒,而有些IP池,一次只能调用10个IP,间隔还要5秒以上,这样的资源只适合个人练手用,如果是企业用户就趁早放弃吧。
3、可用率要高:IP池不但要大IP可用率还得高,因为许多通过扫描公网IP得来的资源,有可能上千万的IP实际可用率不到5%,这样来看能用的IP就非常有限了,而且还会浪费大量的时间去验证IP的可用性,而优秀的爬虫http代理池的IP,一般要确保可用率在90%以上才行。
4、IP资源最好独享,其实这一项跟第三点有点类似,因为独享IP能直接影响IP的可用率,独享http代理能确保每个IP同时只有一个用户在使用,能确保IP的可用率、稳定性。
5、调用方便:这个是指有丰富的API接口,方便集成到任何程序里。
到此,以上就是小编对于的问题就介绍到这了,希望这3点解答对大家有用。
")
")

