

分布式存储如何保证数据的高可用性?
MySQL的分布式存储是什么?
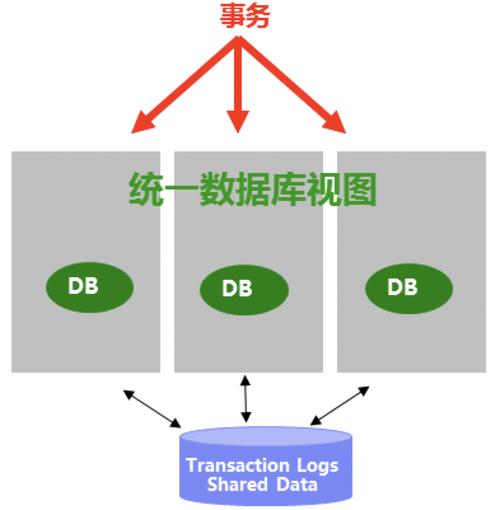
1. MySQL的分布式存储是一种将数据分散存储在多个节点上的技术。2. 这种存储方式的原因是为了解决单节点存储容量和性能的限制。通过将数据分布在多个节点上,可以提高存储容量和读写性能,并且增加系统的可扩展性和容错性。3. 分布式存储可以通过数据分片、数据复制和数据一致性等方式实现。数据分片将数据划分为多个部分存储在不同的节点上,数据复制可以提高数据的可用性和容错性,数据一致性保证了分布式系统中数据的正确性和一致性。同时,分布式存储还可以通过负载均衡和故障自动转移等机制来优化系统的性能和可靠性。
 (图片来源网络,侵删)
(图片来源网络,侵删)分布式存储吃cpu还是内存?
吃内存。
分布式存储就是将数据分散存储到多个存储服务器上,并将这些分散的存储资源构成一个虚拟的存储设备,实际上数据分散的存储在企业的各个角落。分布式存储的好处是提高了系统的可靠性、可用性和存取效率,还易于扩展。
吃Cpu,分布式存储是软件定义存储解决方案的实现,它是通过软件将硬件进行抽象化管理,将集群全部的CPU资源、内存资源、硬盘资源、网络资源等进行池化,组合成统一资源池,然后通过简单友好的管理界面或API提供给用户个性化的存储解决方案。
 (图片来源网络,侵删)
(图片来源网络,侵删)大数据的储存有?
大数据的储存主要有两种方式,一种是分布式储存技术,另一种是云存储技术。分布式储存技术指的是将大数据切分成多个小数据块,分别存储在不同的节点上,通过分布式算法实现数据的高可用性和可扩展性。这种技术的优点是可以自由扩展存储容量,同时也能保证数据的安全性和可靠性。云存储技术则是将大数据存储在云端,通过云计算技术提供用户便捷的存储、备份和共享服务。云存储技术的优点是能够实现数据的自动备份和容灾,同时也可以提高数据的可用性和共享性。此外,还有一些相关的技术,比如提供大规模存储服务的存储设备、高速缓存技术等,这些技术也在大数据储存中得到了广泛的应用和发展。
很多种方式。第一,传统的硬盘是大数据储存中最为常用的方式之一,其价格相对较低,同时具有较高的存储密度和稳定性。第二,固态硬盘在速度、性能和较小的体积等方面都有很大的优势,适用于对速度要求较高的场景。还有网络存储,通过网络连接将数据存储在远程服务器上,实现远程备份和数据共享等功能。最近几年,云存储已经渐成主流,可以实现高可用性、弹性扩展、数据备份等功能,因此也成为大数据存储的首选。综上所述,大数据的储存方式因应用场景和数据规模不同而有所不同,选择合适的储存方式可以提高数据存储的效率和可靠性。
大数据的储存方式有以下几种:
 (图片来源网络,侵删)
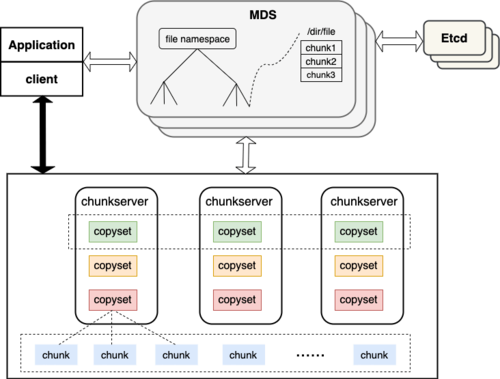
(图片来源网络,侵删)1.分布式文件系统:分布式文件系统(Distributed File System,DFS)是把集群中所有存储节点的存储设备组合起来,提供大规模、高可靠性的文件系统服务。其中比较常用的分布式文件系统包括Hadoop HDFS、Ceph和GlusterFS等。
2.NoSQL数据库:NoSQL(Not Only SQL)是一种灵活的非关系型数据库,适用于存储大量结构化和非结构化数据,具有横向扩展性和高可用性等优势。NoSQL数据库包括MongoDB、Cassandra、HBase和Redis等。
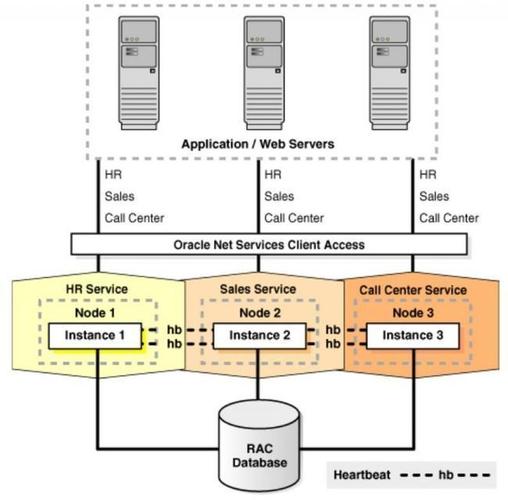
3.数据库集群:数据库集群是指将多个数据库服务器组合在一起,共同承担相同的任务,并通过负载平衡和数据副本等机制实现高性能和高可用性。其中,比较常用的数据库集群包括MySQL Cluster、PostgreSQL和Oracle RAC等。
4.对象存储服务:对象存储服务(Object Storage Service,OSS)是一种面向云计算的海量数据存储服务,通过HTTP/HTTPS协议访问,以大文件对象和对象为单位进行存储和管理,适合存储非结构化的大数据。常见的对象存储服务包括阿里云OSS、腾讯云COS和亚马逊S3等。
综上所述,大数据的存储方式有很多种,可以根据具体的业务需求和技术特点选择合适的存储方案,或结合多种方式进行混合存储。
到此,以上就是小编对于分布式存储如何保证数据的高可用性呢的问题就介绍到这了,希望这3点解答对大家有用。
")
")

