

在分布式存储系统中如何管理和调度存储节点?
什么是分布式文件存储系统?
分布式文件存储系统是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点(可简单的理解为一台计算机)相连;或是若干不同的逻辑磁盘分区或卷标组合在一起而形成的完整的有层次的文件系统。
 (图片来源网络,侵删)
(图片来源网络,侵删)DFS为分布在网络上任意位置的资源提供一个逻辑上的树形文件系统结构,从而使用户访问分布在网络上的共享文件更加简便。
单独的 DFS共享文件夹的作用是相对于通过网络上的其他共享文件夹的访问点。
并行存储与分布式存储区别?
主要区别:
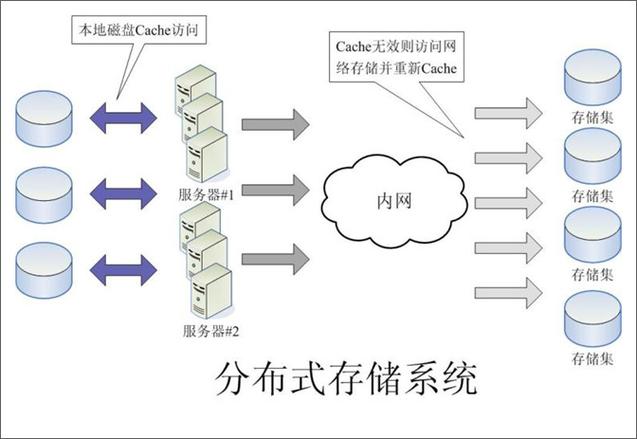 (图片来源网络,侵删)
(图片来源网络,侵删)(1) 应用目标不同。并行数据库系统的目标是充分发挥并行计算机的优势,利用系统中的各个处理机结点并行完成数据库任务,提高数据库系统的整体性能。分布式数据库系统主要目的在于实现场地自治和数据的全局透明共享,而不要求利用网络中的各个结点来提高系统处理性能。(2) 实现方式不同。在具体实现方法上,并行数据库系统与分布式数据库系统也有着较大的不同。在并行数据库系统中,为了充分利用各个结点的处理能力,各结点间可以采用高速网络连接。结点键的数据传输代价相对较低,当某些结点处于空闲状态时,可以将工作负载过大的结点上的部分任务通过高速网传送给空闲结点处理,从而实现系统的负载平衡。但是在分布式数据库系统中,为了适应应用的需要,满足部门分布特点的需要,各结点间一般采用局域网或广域网相连,网络带宽较低,结点间的通信开销较大。因此,在查询处理时一般应尽量减少结点间的数据传输量。(3) 各结点的地位不同。在并行数据库系统中,各结点是完全非独立的,不存在全局应用和局部应用的概念,在数据处理中只能发挥协同作用,而不能有局部应用。在分布式数据库系统中,各结点除了能通过网络协同完成全局事务外,各结点具有场地自治性,每个场地使独立的数据库系统。每个场地有自己的数据库、客户、CPU等资源,运行自己的DBMS,执行局部应用,具有高度的自治性。
并行存储和分布式存储是两种不同的存储体系架构。
并行存储是指多个存储单元通过一定的控制方式组成一个整体,从而形成一个或多个共享存储区域,多个主机可以同时通过高速总线或交换机连接到这个存储空间,共享其中的资源。并行存储的特点是数据传输速度快,适合于高性能计算和数据分析等场景。常见的并行存储设备包括SAN、NAS等。
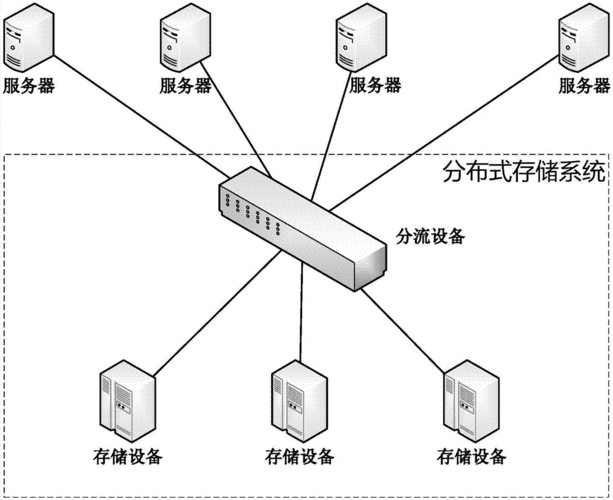 (图片来源网络,侵删)
(图片来源网络,侵删)分布式存储则是将数据分散保存在多台互相独立的计算机节点上,在分布式存储系统中,每个节点都可以处理存储和检索请求,同时也要保证数据的一致性和可靠性。与并行存储相比,分布式存储具有高可扩展性,容错性和异地备份的特点,可以满足海量数据存储的需求。常见的分布式存储系统包括Ceph、Hadoop HDFS等。
两者的主要区别如下:
1.存储方式不同:并行存储是通过多个单元组成一个整体,共享存储空间;而分布式存储则是将数据分散保存在多个节点上。
2.应用场景不同:并行存储主要应用于高性能计算和数据分析等场景,而分布式存储则更适合海量数据存储和分析。
3.数据安全性不同:并行存储的数据安全性相对较低,因为共享存储区域中的数据很容易受到其他节点的访问和篡改;而分布式存储则采用多副本存储和容错机制来保证数据的安全性。
4.数据传输方式不同:并行存储需要高速总线或交换机来实现数据传输,而分布式存储则通过网络传输数据。
综上所述,两种存储体系有各自的特点和优势,在不同场景下应选取适合的存储系统。
到此,以上就是小编对于分布式调度和存储的最小单元的问题就介绍到这了,希望这2点解答对大家有用。
")
")

