

如何利用python爬取网页数据?(怎么用python爬取网站数据)
如何利用python爬取网页数据?
利用 Python 爬取网页数据的基本步骤如下:
 (图片来源网络,侵删)
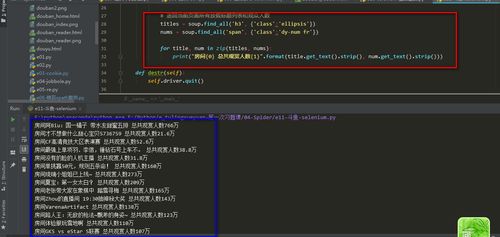
(图片来源网络,侵删)1.选择合适的爬虫框架,例如 BeautifulSoup、Scrapy 等。
2.确定需要爬取的网页 URL,并使用 Python 中的requests库或其他网络库发送 HTTP 请求。
 (图片来源网络,侵删)
(图片来源网络,侵删)3.解析网页内容,可以使用 BeautifulSoup 等库解析 HTML 或 XML 内容。
4.提取需要的信息,可以使用正则表达式、XPath 等方法从解析后的网页内容中提取所需的数据。
要利用Python爬取网页数据,可以使用库如requests、BeautifulSoup或Scrapy。
 (图片来源网络,侵删)
(图片来源网络,侵删)第一,使用requests库获取网页内容,然后可以使用BeautifulSoup解析HTML或Scrapy进行网页抓取和数据提取。
可以使用定位器和选择器来定位特定元素,并提取相关数据。然后可以将所需的数据保存到数据库、文件或进行进一步的处理。务必遵守网站的robots.txt文件和遵循法律规定,以及避免对目标网站造成过大的压力和影响。
要利用Python爬取网页数据,第一需要安装和使用合适的爬虫工具,如BeautifulSoup、Scrapy或者Requests。
然后,通过编写Python代码,使用HTTP请求获取网页内容,再通过解析网页结构和提取数据的方法,从网页中提取所需的信息。
最后,将提取的数据存储到本地文件或数据库中。需要注意的是,爬取过程中要遵守网站的使用规则和法律法规,不得违反网站的Robots协议或使用爬虫进行非法行为。
Python如何爬取网页文本内容?
用python爬取网页信息的话,需要学习几个模块,urllib,urllib2,urllib3,requests,httplib等等模块,还要学习re模块(也就是正则表达式)。根据不同的场景使用不同的模块来高效快速的解决问题。
最开始我建议你还是从最简单的urllib模块学起,比如爬新浪首页(声明:本代码只做学术研究,绝无攻击用意):
这样就把新浪首页的源代码爬取到了,这是整个网页信息,如果你要提取你觉得有用的信息得学会使用字符串方法或者正则表达式了。
平时多看看网上的文章和教程,很快就能学会的。
补充一点:以上使用的环境是python2,在python3中,已经把urllib,urllib2,urllib3整合为一个包,而不再有这几个单词为名字的模块。
python爬虫如何爬取数据生成excel?
你可以使用Python库中的pandas和openpyxl模块来生成Excel。其中,pandas模块用于读取和处理数据,openpyxl模块则可以用于生成Excel文档。
下面是一个简单的示例代码,演示如何通过Python爬虫获取网页数据并将其导出为Excel文件:
python
import requests
import pandas as pd
from openpyxl import Workbook
# 发送GET请求获取HTML
url = 'https://www.example.com'
res = requests.get(url)
html_data = res.text
到此,以上就是小编对于利用python爬取简单网页数据步骤的问题就介绍到这了,希望这3点解答对大家有用。



