

python+selenium怎么定位页面弹窗的元素?(python定位元素的方法)
python+selenium怎么定位页面弹窗的元素?
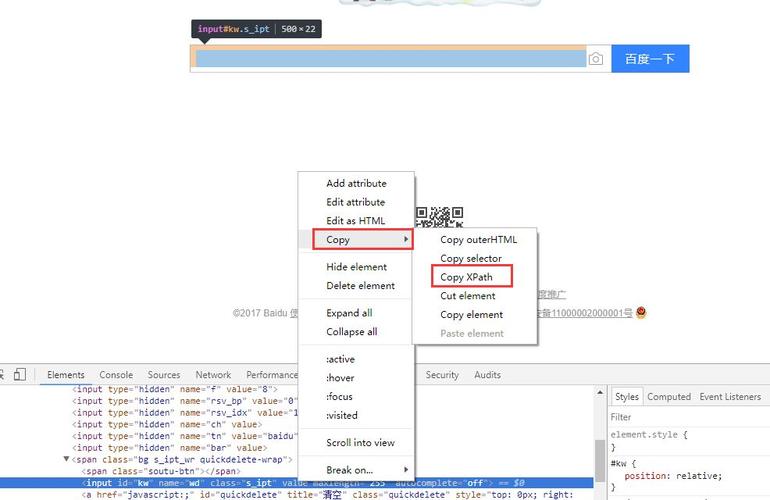
定位页面元素//通过Id定位元素WebElement element = driver.findElement(By.id(“id名"))
 (图片来源网络,侵删)
(图片来源网络,侵删);//通过name定位元素WebElement element = driver.findElement(By.name(“name名"))
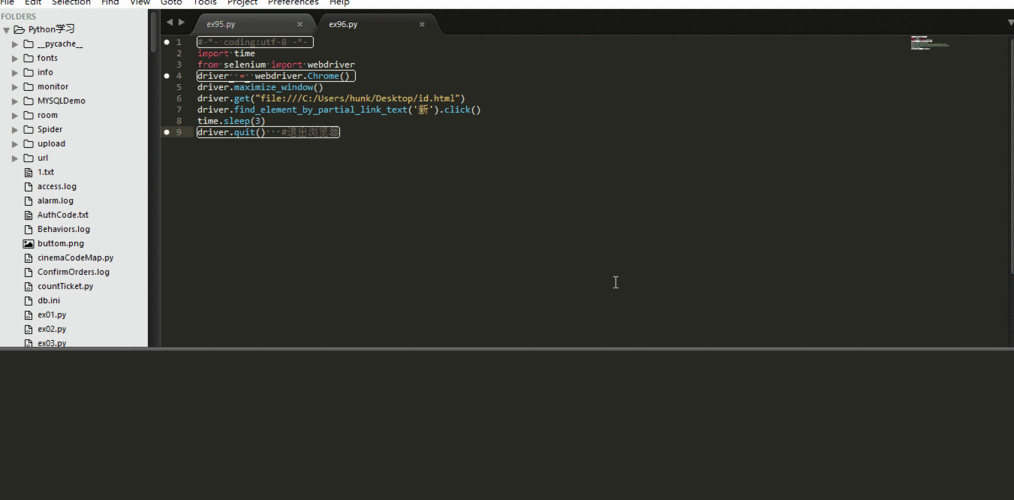
;//通过xpath定位元素WebElement element = driver.findElement(By.xpath(“xpath路径"))
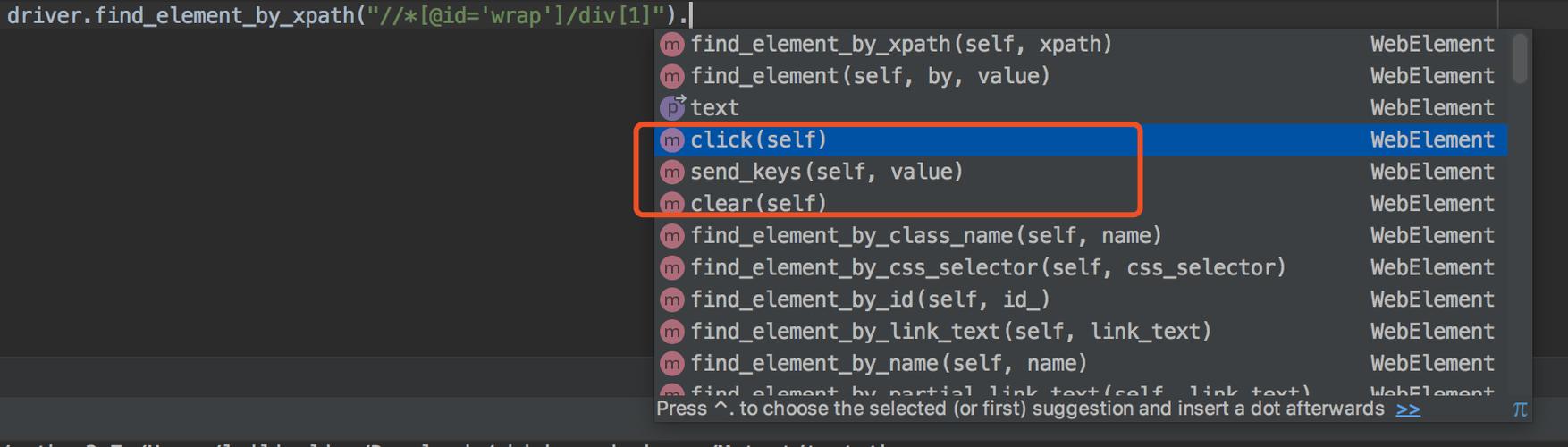
;//通过标签的值定位元素WebElement cheese = driver.findElement(By.linkText(“标签的值"))
 (图片来源网络,侵删)
(图片来源网络,侵删);//通过class的值定位元素List list=driver.findElements(By.className(“class值"))
;//通过标签名定位元素List list = driver.findElements(By.tagName(“标签名"));
python查询列表第几位的元素?
在Python中,可以使用索引来查询列表中的元素。列表的索引从0开始,表示第一个元素,依次递增。要查询列表中的第n个元素,可以使用索引n-1。
 (图片来源网络,侵删)
(图片来源网络,侵删)例如,假设有一个列表my_list,要查询第3个元素,可以使用以下代码:
element = my_list[2]
在这个例子中,my_list[2]表示列表my_list中的第3个元素,因为索引是从0开始的。
需要注意的是,如果指定的索引超出了列表的范围,将会引发IndexError异常。因此,在查询列表元素之前,最好先检查列表的长度或使用异常处理机制来处理可能的索引错误
python怎么爬数据?
Python可以通过以下步骤来爬取数据:1. 导入所需的库,如requests和BeautifulSoup。2. 使用requests库发送HTTP请求,获取目标网页的内容。3. 使用BeautifulSoup库解析网页内容,提取所需的数据。4. 对提取的数据进行处理和清洗,使其符合需求。5. 将处理后的数据保存到文件或数据库中,或进行进一步的分析和可视化。Python是一种功能强大且易于学习的编程语言,拥有丰富的第三方库和工具,使其成为数据爬取的首选语言。requests库可以方便地发送HTTP请求,BeautifulSoup库可以灵活地解析HTML或XML文档,两者的结合可以快速、高效地爬取网页数据。除了requests和BeautifulSoup库,还有其他一些常用的库可以用于数据爬取,如Scrapy、Selenium等。此外,爬取数据时需要注意网站的反爬机制和法律法规的限制,遵守爬虫道德规范,以确保合法、合规的数据获取。同时,数据爬取也需要考虑数据的存储和处理方式,以便后续的数据分析和应用。
Python 是一种功能强大的编程语言,被广泛用于数据爬取任务。下面是使用 Python 进行数据爬取的一般步骤:
1.确定目标网站:第一,您需要确定要爬取数据的目标网站。了解目标网站的结构和数据来源,以便选择合适的工具和技术。
2.选择合适的库和工具:Python 提供了许多用于数据爬取的库和工具,如 BeautifulSoup、Scrapy、Selenium 等。根据目标网站的特点和需求,选择适合的库和工具。
3.发送 HTTP 请求:使用 Python 的库(如 requests)向目标网站发送 HTTP 请求,获取网页的 HTML 内容。
4.解析 HTML 内容:使用选择的库(如 BeautifulSoup)解析 HTML 内容,提取所需的数据。
到此,以上就是小编对于python 定位元素的问题就介绍到这了,希望这3点解答对大家有用。



