

saga分布式事务详解?(如何避免分布式存储系统的单点故障问题?)
saga分布式事务详解?
1. saga分布式事务是一种用于解决分布式系统中事务一致性问题的机制。2. 传统的两阶段提交协议在分布式系统中存在单点故障和阻塞的问题,而saga分布式事务通过将一个大事务拆分成多个小事务,并采用补偿机制来保证最终一致性。 在saga中,每个小事务都有一个对应的补偿操作,当某个小事务失败时,可以执行相应的补偿操作来回滚之前的操作,从而保证系统的一致性。 这种机制可以提高系统的可用性和性能,并且能够容忍部分故障。3. 值得注意的是,saga分布式事务并不适用于所有场景,对于一些强一致性要求较高的业务场景,可能需要采用其他更为严格的分布式事务机制。同时,saga分布式事务的实现也需要考虑到补偿操作的正确性和幂等性等问题。
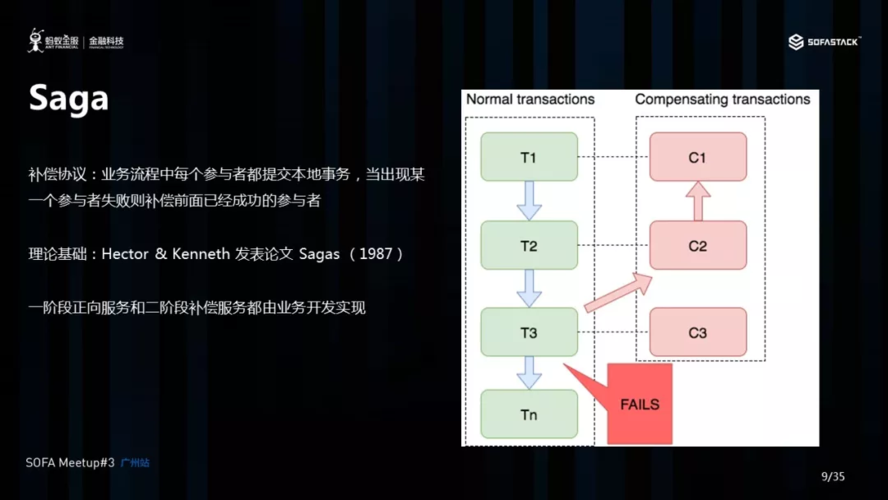 (图片来源网络,侵删)
(图片来源网络,侵删)1、Saga分布式事务是一种用于解决分布式系统中跨多个服务的事务一致性问题的方法。
2、它通过将一个大的事务拆分成一系列小的子事务,并在每个子事务的前后添加可逆操作以保证事务最终一致性。
3、Saga分布式事务的优势在于能够以较低的性能开销实现事务一致性,并能够部分回滚,避免了单点故障的风险。
 (图片来源网络,侵删)
(图片来源网络,侵删)指一次大的操作由不同的小操作组成的,这些小的操作分布在不同的服务器上,分布式事务需要保证这些小操作要么全部成功,要么全部失败。从本质上来说,分布式事务就是为了保证不同数据库的数据一致性
IT运维管理如何摆脱“不怕坏?
1、备份备份再备份
2、修改生产环境前在测试环境做充分测试,并详细记录每一步操作过程
 (图片来源网络,侵删)
(图片来源网络,侵删)3、执行DML语句务必再三确认
4、自动脚本从小功能开始,逐步扩充功能,避免差错
5、对硬件勤维护勤保养
6、花钱买安全,磁盘阵列冗余允许坏两块的比允许坏一块的安全;能上的安全设备都上,减少病毒的破坏
啰嗦一句,那另一个回答的是啥呀,这个问题和苹果公司有毛关系。
回答,如何“不怕坏“
这里我理解就是如何保证系统环境和硬件的稳定性,我们看到这个问题第一个想到的就是,备份冗余。其实还有其它
1、第一你得有一套完备的软件硬件监控报警平台,这样你可以在发生问题时第一时间响应,IT运维就是早发现早解决,越拖问题越大。所以你要第一时间可以响应。
2、任何环境都有关键和非关键之分,每套环境你要合理判断它的关键级别,要试想那些关键设备万一坏了多久能解决,是否可以解决,有备份方案吗?
3、这里给各位说几个“不怕坏”个经验,
1)关键服务器做raid最好做一个spare,要考虑到万一坏了两块呢?
2}一定要养成关键系统及应用备份的好习惯。哪怕是交换机的配置,最好也要定期做备份。
3}安全问题,软件的合规性、补丁打完整、病毒库更新。
就说到这吧,其实还有很多,关键一点就是你有没有把你的运维环境当回事,如果把它当成你的孩子,你要提前想到的准备的工作会更多,准备了那么多如果还有一些不可控因素导致坏了,那只能建议拜拜。
不怕坏第一得有冗余备份
1,怕磁盘坏?服务器上的本地硬盘很多,第一必须做raid,除开raid0以外都可以避免单个磁盘损坏,最常见的就是raid5,raid0+1或者1➕0。
2,怕服务器坏?第一,现在大规模服务器集群普遍采用分布式或者高可用架构,目的之一为了解决单个服务器故障影响整体服务运行,第二采用虚拟化技术,在底层物理机上抽象一层服务器环境,通过虚拟机自身的容错机制解决服务器单点故障问题,最后采用容器集群技术,比如k8s,通过容器编排工具的调度机制解决单点故障
到此,以上就是小编对于分布式存储节点的问题就介绍到这了,希望这2点解答对大家有用。
")
")

