

python 读取文件每一行,Python循环读取文件的每一行
python怎么循环遍历每行有多少?
直接使用简单的for循环结构[ for i in list: print(list) ],其中代码中的 i 可以自由命名,代码中的 list 为列表的名称,冒号后面的代码换行并缩进。利用range() 函数跟len() 函数。这种方法可以输出序列号,也可以不输出。
 (图片来源网络,侵删)
(图片来源网络,侵删)利用enumerate() 函数。这种方法可以输出序列号,也可以不输出。利用iter() 函数。这种方法可以输出序列号,也可以不输出
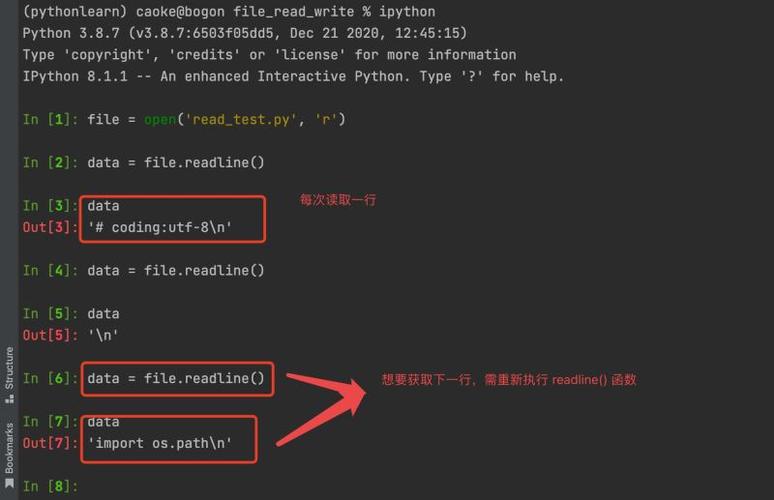
在Python中,您可以通过使用for循环遍历每一行,并获取每行的字符数量。以下是两种常见的方法:
方法1:使用splitlines()和len()函数
 (图片来源网络,侵删)
(图片来源网络,侵删)python
text = '''
Hello
 (图片来源网络,侵删)
(图片来源网络,侵删)World
Welcome to Python
'''
python怎么自动批量读取文件夹下的excel?
Python批量读取特定文件夹下Excel的话,主要分为2步,第一根据后缀名(xls或xlsx)匹配出所有Excel文件,然后直接利用相关模块(pandas,openpyxl等)读取即可,下面我简单介绍一下实现过程,感兴趣的朋友可以尝试一下:
01
查找所有Excel文件
这一步非常简单,主要是根据后缀名匹配所有Excel文件,基本思路先使用os.walk函数遍历指定的文件夹,找到所有文件,然后一一匹配文件后缀名,如果是xls或xlsx,则为Excel文件,添加到list列表,之后返回,后面读取函数就是根据这个列表(存储所有搜索到的Excel文件路径)读取Excel文件:
02
读取Excel文件内容
这一步主要你是根据上一步找到的Excel文件路径直接读取Excel文件,至于读取模块或库的话,那就非常多啦,基本的xlrd,xlutils,openpyxl都行,最简单的方式就是使用pandas,一个著名的数据处理库,内置了大量函数和类型,可以轻松处理Excel等日常各种文件,安装的话,直接在cmd窗口输入命令“pip install pandas”即可:
安装完成后,我们就可以直接使用pandas库读取Excel文件了,非常简单,只需要一行代码即可搞定,也就是read_excel函数,传入Excel文件路径就行,默认情况下会读取列标题,如果你不需要列标题的话,设置header=None即可,读取的数据类型为DataFrame,后续处理的话,也非常方便:
python如何判断读取的文件是否有下一回?
在 Python 中,可以使用以下方法来判断读取的文件是否有下一回:
1.使用 EOF 标记:在读取文件时,可以使用一个标记来表示文件的结束。例如,在 Python 中,可以使用 sys.EOFError 来表示文件结束。当读取文件时,如果遇到 EOFError,则表示文件已经结束,没有下一回。
2.使用计数器:在读取文件时,可以使用一个计数器来记录读取的字节数。如果计数器达到文件的大小,则表示文件已经结束,没有下一回。
3.使用 tell 和 seek 函数:在读取文件时,可以使用 tell 函数获取当前的文件位置,然后使用 seek 函数将文件位置设置为文件的开头。如果 seek 函数返回 0,则表示文件已经结束,没有下一回。
以上方法可以根据具体的需求和场景选择使用。例如,如果需要在读取文件时进行复杂的处理,可以使用计数器或 tell 和 seek 函数;如果只需要简单地判断文件是否有下一回,可以使用 EOF 标记。
到此,以上就是小编对于python读取文件中的每一行的问题就介绍到这了,希望这3点解答对大家有用。
")
")

