

如何在html中嵌入Python脚本?(python调用html文件,html调用python运行结果)
如何在html中嵌入Python脚本?
用Gestalt能够改变现状的Javascript库与Silverlight结合后,它可以让开发者直接在HTML中嵌入Python,在查看站点源代码时,会看到类似这样的代码:
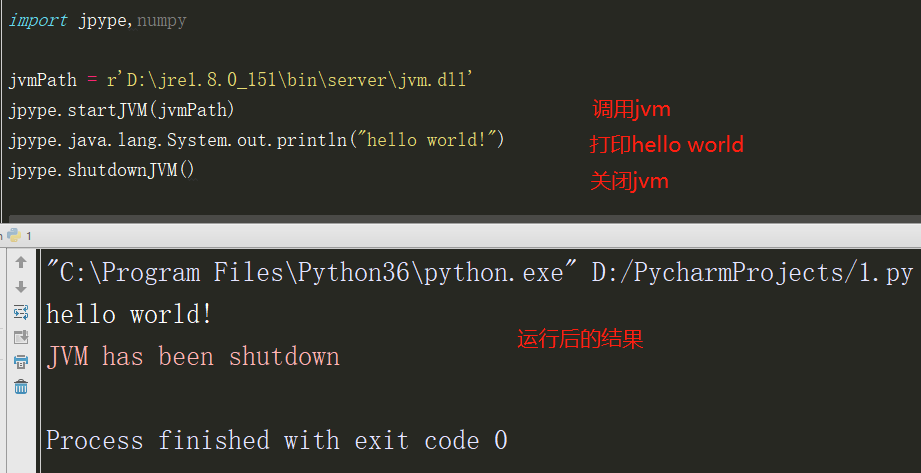 (图片来源网络,侵删)<script language="python">
(图片来源网络,侵删)<script language="python">将这句话包含在页面顶部,这就是在着手写Python前所要做的所有准备。它会将内联的Python代码传给Silverlight运行时,该运行时支持Dynamic Language Runtime。
如何将python代码嵌入html代码中?
用Gestalt能够改变现状的Javascript库与Silverlight结合后,它可以让开发者直接在HTML中嵌入Python,在查看站点源代码时,会看到类似这样的代码:
<script language="python">
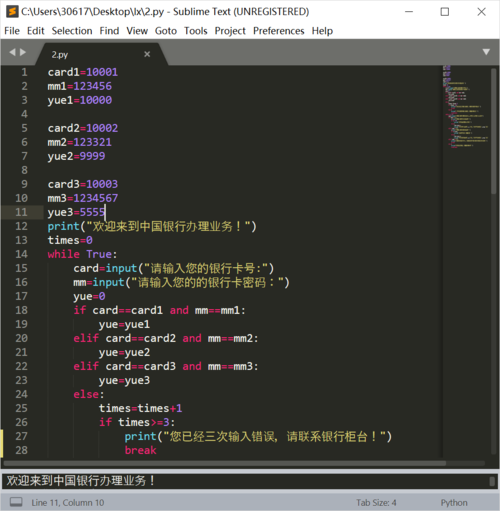 (图片来源网络,侵删)
(图片来源网络,侵删)将这句话包含在页面顶部,这就是在着手写Python前所要做的所有准备。它会将内联的Python代码传给Silverlight运行时,该运行时支持Dynamic Language Runtime。
如何用python爬取数据?
Python可以通过以下步骤来爬取数据:1. 导入所需的库,如requests和BeautifulSoup。
2. 使用requests库发送HTTP请求,获取目标网页的内容。
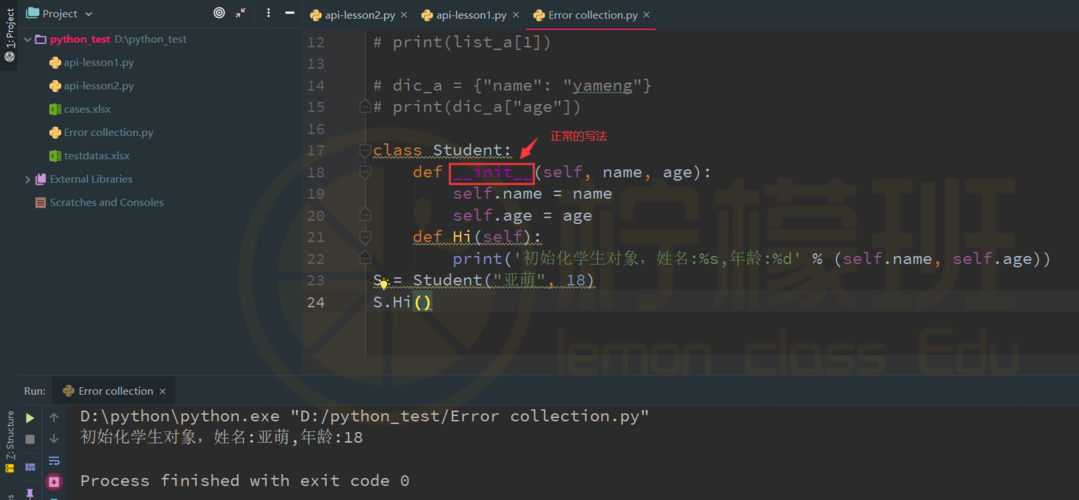 (图片来源网络,侵删)
(图片来源网络,侵删)3. 使用BeautifulSoup库解析网页内容,提取所需的数据。
4. 对提取的数据进行处理和清洗,使其符合需求。
5. 将处理后的数据保存到文件或数据库中,或进行进一步的分析和可视化。
Python是一种功能强大且易于学习的编程语言,拥有丰富的第三方库和工具,使其成为数据爬取的首选语言。
requests库可以方便地发送HTTP请求,BeautifulSoup库可以灵活地解析HTML或XML文档,两者的结合可以快速、高效地爬取网页数据。
除了requests和BeautifulSoup库,还有其他一些常用的库可以用于数据爬取,如Scrapy、Selenium等。
此外,爬取数据时需要注意网站的反爬机制和法律法规的限制,遵守爬虫道德规范,以确保合法、合规的数据获取。
同时,数据爬取也需要考虑数据的存储和处理方式,以便后续的数据分析和应用。
在Python中,你可以使用各种库来爬取数据,其中最常用的可能是 requests、BeautifulSoup 和 Scrapy。下面我将给你展示一个基本的网页爬取例子。在这个例子中,我们将使用 requests 和 BeautifulSoup 来爬取网页上的数据。
第一,你需要安装这两个库。如果你还没有安装,可以通过以下命令来安装:
python
pip install requests beautifulsoup4
接下来是一个基本的爬虫程序示例,这个程序将爬取一个网页上的所有链接:
python
import requests
from bs4 import BeautifulSoup
def get_links(url):
response = requests.get(url)
到此,以上就是小编对于html 调用python的问题就介绍到这了,希望这3点解答对大家有用。
")
")

