

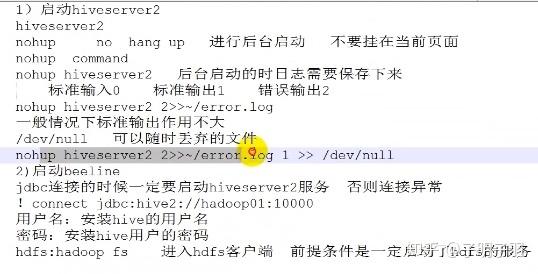
hive和beeline命令的区别?(beeline执行hive文件,使用beeline连接hive数据库)
hive和beeline命令的区别?
答:hive和beeline命令有三种区别:
 (图片来源网络,侵删)
(图片来源网络,侵删)内嵌区别、本地区别、远程区别。
内嵌区别:元数据保村在内嵌的derby中,允许一个会话链接,尝试多个会话链接时会报错。
本地区别:本地安装mysql 替代derby存储元数据。
 (图片来源网络,侵删)
(图片来源网络,侵删)由于元数据的获取需要访问mysql,所以这就要求每一个用户必须要有对MySQL的访问权利。
远程区别:以本地模式为基础。
mysql数据库所在的节点提供metastore service服务,其他节点可以连接该服务来获取元数据信息。
 (图片来源网络,侵删)
(图片来源网络,侵删)各种客户端通过 beeline 来连接,连接之前无需知道数据库的用户名和密码。
1. hive和beeline命令有明显的区别。2. hive命令是用于在Hadoop集群上进行数据仓库查询和分析的工具,它使用HiveQL语言来查询和处理数据。而beeline命令是Hive的一个JDBC客户端,它可以通过JDBC连接到Hive服务器,并执行HiveQL查询。3. 除了在Hadoop集群上进行查询和分析之外,hive命令还可以用于数据仓库的建模和ETL操作。而beeline命令则更适合于需要在Java应用程序中使用Hive的情况。
Hive和Beeline是两个不同的命令行工具,用于操作Hadoop生态系统中的数据。
Hive是较早的命令行工具,它提供了一种基于SQL的接口来操作存储在Hadoop集群中的数据。Hive通过将SQL转换为MapReduce任务来实现数据查询和处理。Hive命令的特点是它通过MetaServer访问元数据,使用CliDriver进行本地直接编译,然后访问MetaStore,提交作业。然而,Hive命令的参数相对较少,不支持像Beeline那样的更灵活的表达方式。
Beeline是一个更新的命令行工具,它提供了更灵活和强大的功能。Beeline通过连接HiveServer2来实现数据的查询和处理,而HiveServer2提供了更多的安全性和多用户支持。Beeline命令可以携带更丰富的参数,例如使用--showHeader=false和--outputformat=dsv等参数。
总的来说,Hive和Beeline命令的区别在于它们的架构和功能。Hive是一个较早的工具,它基于SQL并提供了基本的查询和处理功能,而Beeline是一个更新的工具,提供了更灵活和强大的功能,并支持更多的安全性和多用户。
Hive和Beeline都是与Apache Hive交互的工具,但是它们有不同的用途和特点。
Hive是一个在Hadoop上运行的数据仓库工具,允许用户使用SQL查询语言处理大型数据集。Hive使用HiveQL语言,这是与SQL类似但含有Hadoop生态系统特定功能和语法的查询语言。Hive还支持在Hadoop集群中分布式处理数据,可以运行在不同的操作系统上。
Beeline是一个使用JDBC连接HiveServer2的命令行工具,允许用户使用SQL查询语言交互式处理数据。它支持与HiveServer2的通信,并支持多种认证方式,例如Kerberos和LDAP。Beeline还可以支持以交互方式输入SQL命令并获取结果,可以在不同的操作系统上运行。
在使用Hive时,可以使用Hive CLI命令行界面或使用Beeline进行交互。然而,Hive CLI已经过时,推荐使用Beeline代替它进行交互和查询。因此,Beeline拥有更好的灵活性和更广泛的适用性,并且支持复杂的认证和Error输出更加详细。
到此,以上就是小编对于beeline连接hive执行sql的问题就介绍到这了,希望这1点解答对大家有用。
")
")

