

python怎么爬数据?(python爬虫抓取数据的步骤是什么)
python怎么爬数据?
Python可以使用多种库和框架来爬取数据,其中最常用的是Requests和BeautifulSoup。
 (图片来源网络,侵删)
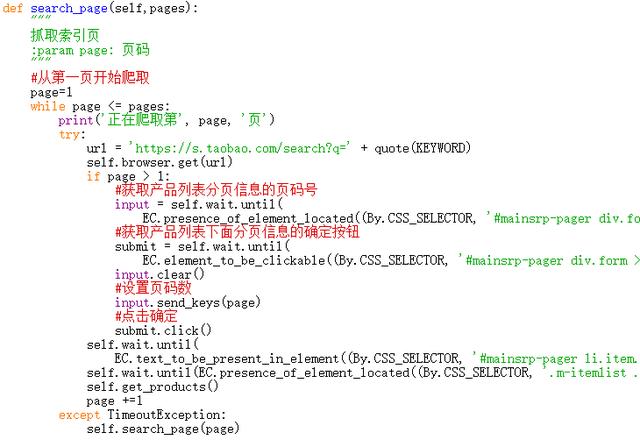
(图片来源网络,侵删)以下是使用Requests和BeautifulSoup进行爬虫的基本步骤:
1. 导入所需库和模块:
```python
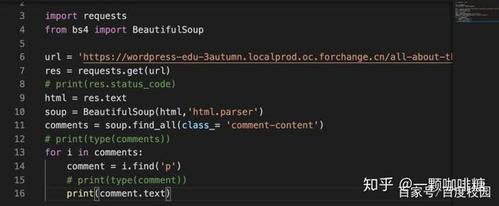 (图片来源网络,侵删)
(图片来源网络,侵删)import requests
from bs4 import BeautifulSoup
```
 (图片来源网络,侵删)
(图片来源网络,侵删)Python可以通过以下步骤来爬取数据:1. 导入所需的库,如requests和BeautifulSoup。2. 使用requests库发送HTTP请求,获取目标网页的内容。3. 使用BeautifulSoup库解析网页内容,提取所需的数据。4. 对提取的数据进行处理和清洗,使其符合需求。5. 将处理后的数据保存到文件或数据库中,或进行进一步的分析和可视化。Python是一种功能强大且易于学习的编程语言,拥有丰富的第三方库和工具,使其成为数据爬取的首选语言。requests库可以方便地发送HTTP请求,BeautifulSoup库可以灵活地解析HTML或XML文档,两者的结合可以快速、高效地爬取网页数据。除了requests和BeautifulSoup库,还有其他一些常用的库可以用于数据爬取,如Scrapy、Selenium等。此外,爬取数据时需要注意网站的反爬机制和法律法规的限制,遵守爬虫道德规范,以确保合法、合规的数据获取。同时,数据爬取也需要考虑数据的存储和处理方式,以便后续的数据分析和应用。
要使用Python进行数据爬取,第一需要选择一个合适的爬虫库,如Requests或Scrapy。
然后,通过发送HTTP请求获取网页内容,并使用解析库(如BeautifulSoup或XPath)对页面进行解析,从中提取所需数据。
可以使用正则表达式或CSS选择器来定位和提取特定的数据元素。
进一步,通过循环遍历多个页面或使用递归方法实现深度爬取。此外,还应注意网站规则和反爬措施,并设置适当的Headers和代理,以避免被封IP或限制访问。
最后,将提取的数据存储到数据库、文本文件或其他数据格式中,以供进一步分析和处理。
Python 是一种功能强大的编程语言,被广泛用于数据爬取任务。下面是使用 Python 进行数据爬取的一般步骤:
1.确定目标网站:第一,您需要确定要爬取数据的目标网站。了解目标网站的结构和数据来源,以便选择合适的工具和技术。
2.选择合适的库和工具:Python 提供了许多用于数据爬取的库和工具,如 BeautifulSoup、Scrapy、Selenium 等。根据目标网站的特点和需求,选择适合的库和工具。
3.发送 HTTP 请求:使用 Python 的库(如 requests)向目标网站发送 HTTP 请求,获取网页的 HTML 内容。
4.解析 HTML 内容:使用选择的库(如 BeautifulSoup)解析 HTML 内容,提取所需的数据。
到此,以上就是小编对于python爬虫爬取数据的问题就介绍到这了,希望这1点解答对大家有用。



