

hdfs如何实现数据的分块和复制?(合并hdfs文件,怎么删除hdfs的某个目录下的文件)
hdfs如何实现数据的分块和复制?
背景知识:
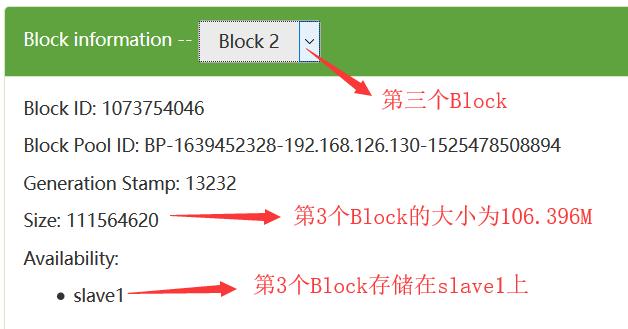 (图片来源网络,侵删)
(图片来源网络,侵删)1、HDFS采用多副本方式对数据进行冗余存储,即一个数块的多个副本分布到不同的数据节点上。
2、集群内部发起写操作请求,把第一个副本放置在发起写操作请求的数据节点上,实现就近写入数据。
如果来自集群外部写操作请求,命名空间从集群中挑选一台磁盘不太满、CPU不太忙的数据节点,作为第一个副本存放地
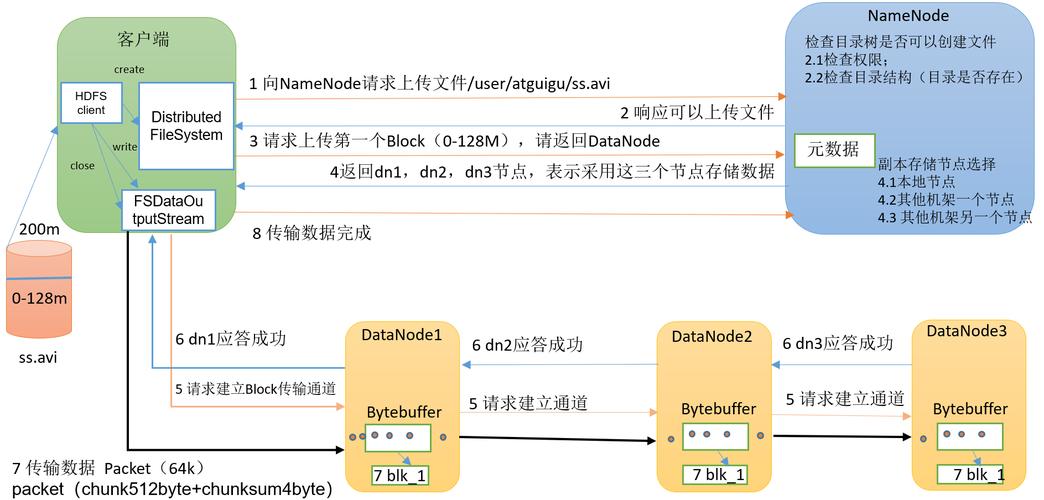 (图片来源网络,侵删)
(图片来源网络,侵删)3、第二个副本放置在与第一个副本不同机架上的数据节点上
4、第三个副本放置在与第一个副本相同机架上的其他节点
5、如果还有多个副本,继续从集群中随机选择数据节点进行存放 。
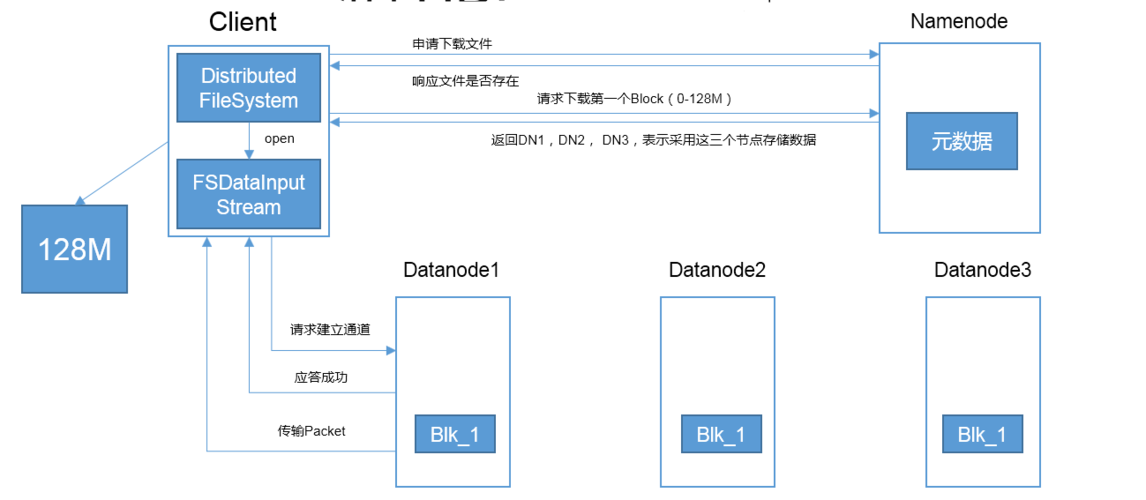 (图片来源网络,侵删)
(图片来源网络,侵删)数据复制技术:
1、当客户端要往HDFS中写入一个文件时,该文件第一写入本地,并切分成若干文件块,每个文件块的大小由HDFS的设定值来决定。
2、每个数据块向名称节点发起写请求,名称节点会根据集群中数据节点的使用情况,选择一个数据节点列表返回给客户端。
hdfs和文件存储关系?
HDFS是建立在本地文件系统之上的,HDFS是通过操作本地文件系统来存储数据的。
hadoop是在现有的文件系统上抽象了一层,但不全是本地文件系统。为提供对不同数据访问的一致接口,hadoop借鉴了Linux的虚拟文件系统概念,引入了Hadoop抽象文件系统,并在此基础上,提供了大量的具体实现。HDFS是其中的一个实现。Amazon S3系统、FTP(网络)、webhdfs(网络)、ramfs(内存)、har等,都是这个抽象文件系统的实现。
hdfs是更高层次的文件系统的抽象,将多台机器组成的文件系统看成一个逻辑上的整体。
hdfs可以存储非结构化文件吗?
可以的。
Hadoop的HDFS可以存储结构化和非结构化类型的文件。
HDFS专为解决大数据存储问题而产生的,其具备了以下特点:
1) HDFS文件系统可存储超大文件。
2) 一次写入,多次读取
一个文件经过创建、写入和关闭之后就不需要改变,这个假设简化了数据一致性的问题,同时提高数据访问的吞吐量。
3) 运行在普通廉价的机器上
Hadoop的设计对硬件要求低,无需昂贵的高可用性机器上,因为在HDFS设计中充分考虑到了数据的可靠性、安全性和高可用性。
到此,以上就是小编对于合并hdfs文件,怎么删除hdfs的某个目录下的文件的问题就介绍到这了,希望这3点解答对大家有用。
")
")

